Minden bizonnyal a videózással már régóta foglalkozóknak semmi újdonság nem lesz ebben a cikkben, hiszen számukra a szín-almintavételezés ismerete olyan, mint egy fotósnak a RAW, vagy inkább a színmélység.
Míg állóképeknél igazság szerint nem sok jelentősége van a szín-almintavételezésnek (vagy angol szakszóval „color subsampling”-nek), a videóknál, főleg a nagy felbontású, de korlátozott sávszélességben használható videófájlok vagy stream-ek esetében, igenis fontos.
Színábrázolási módok
A szín-almintavételezés megértéséhez első körben kicsit másként kell lássuk a színábrázolást, illetve nem árt bepillantanunk abba, hogyan is lehet a képi információk csökkentésével (képtömörítéssel) úgy visszább venni a szükséges adatmennyiséget, hogy az ne befolyásolja nagyon károsan a végső megjelenést.
RGB
Mint tudjuk, a legegyszerűbb színábrázolási mód, amikor egy képnél a képpontok vörös (Red), zöld (Green) és kék (Blue) összetevőit adjuk meg (gyakorlatilag a fényképezőgépek szinte mindegyike pontosan így érzékeli a színeket, a vörös, zöld és kék Bayer-alapszínszűrő közbeiktatásával, amikor is egy-egy pixel csak a kék, csak a vörös vagy csak a zöld színre lesz érzékeny).
Az RGB színhasználat előnye, hogy könnyen kódolható, hardverileg nincs komoly számítási igénye, könnyen adaptálható a kijelzőkhöz is – hiszen ezek is RGB módú megjelenítők.

Egy kép és annak RGB összetevői:




CMYK
A nyomdaiparban a használt festékek (és a szubsztraktív színkeverési elv) miatt a CMYK színábrázolást használják inkább, amelynél a cián (Cyan), bíbor (Magenta), sárga (Yellow) összetevők mellett még egy sötétséget jelző fekete (blacK) értéket is használnak (a cián, sárga és bíbor teljes összekeverésével csak egy sötétszürke színt kapunk, a fekete eléréséhez ezt tovább kell sötétítenünk).

Egy kép és annak CMYK összetevői:




YCbCr
Míg a fenti két színábrázolásoknál az egyes összetevők abszolút értékeit rögzítjük (azaz pl RGB-nél 0 vörös, 0 kék, 0 zöld a feketét jelenti, míg ezek maximum értékei a fehéret), az YCrCB színábrázolás esetében csak az Y, mint luminancia (világosság) számít abszolút értékűnek (0 teljesen sötét, a maximum pedig a teljesen világosat jelzi), a Cr (Chroma red-green) és Cb (Chroma blue-yellow) előjeles értékek (ha az Yc és Yb értékek mindegyike maximumon van, akkor zöldes-sárgát kapunk).
Ennek oka, hogy itt egy szám nem csak egyetlen szín világosságát (RGB-nél) vagy sötétségét (CMYK) jelzi , hanem magát a színt is jelöli, hiszen a minimum érték a Cr esetében vöröset, a maximum érték zöldet jelent, míg Cb-nél a minimum érték kéket, a maximum érték sárgát. Tehát pl. 8 bites színmélység esetén a -127 Cr jelenti a vöröset, míg a +127 a zöldet.
Könnyebb lesz megérteni az YCrCB színábrázolást, ha ismét egy színskálát mutatunk, majd pedig egy YCrCB módon szétszedett képet.




Az teljesen egyértelmű, hogy míg az RGB és CMYK színábrázolást valahogy fel tudjuk fogni és érezzük az okokat, az YCrCb-t elég nehéz értelmezni.
De most elég, ha elfogadjuk, hogy ebből a színábrázolásból is ki lehet hozni azt a megjeleníthető végeredményt, amit általában szeretnénk látni akár egy tévé képernyőn, akár okostelefonon, akár nyomtatásban.
Az RGB és YCbCr színábárzolás között természetesen van átjárás oda és vissza is, de nem túl egyszerű az algoritmus. Nagyjából az alábbi mátrix írja le a műveletet:
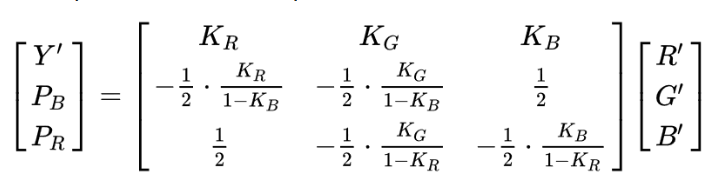
Ugye milyen szép? 🙂
Amit mindenképpen látnunk kell, hogy míg az RGB és CMYK színábrázolások esetében akármelyik csatornát is nézzük külön, mindegyiken ott van jól értelmezhetően a képi részletezettség, azaz felismerhető, hogy mi van a képen, az YCrCb esetében ez csak az Y csatornáról mondható el. A színben gazdagabb Cr csatorna képe már nehezebben felismerhető, míg a kevésbé színgazdag Cb alapján szinte lehetetlenség megmondani, hogy mi is látható az adott képen.
Ebből eredendően az is igaz kell legyen, hogy ha az RGB, vagy CMYK színábrázolású kép esetében csökkentjük az információtartalmat, akkor ez jelentős minőségromlással jár, míg az YCrCB esetében ez akkor igaz csak, ha az információveszteség az Y (luminancia – világosság) csatornát érinti. Az Yc és Yb csatornák eleve információszegények, ezeket veszteségesen tömörítve, vagy pusztán az információk egy részét kidobva sem kapunk nagyon rossz minőségű képet, hiszen a képi részleteket, avagy a képélességet az Y (luminancia) csatorna közvetíti.
Az YCrCb színábrázolás gyakorlatilag megegyezik a Photoshopban elérhető Lab színmóddal, amit sokan használnak utómunkák során arra az esetre, ha a részleteket meg kell hagyni, de a színeken kell kis mértékű korrekciókat végezni.
Képi információ vesztés
Mi történik tehát akkor, ha pl. egy RGB kép egyik csatornájánál (mondjuk a zöldnél) kisebb információmennyiséget engedünk.
Könnyű belátni, hogy mivel az RGB képnél minden egyes csatorna részt vesz a részletgazdagság visszaadásában, az így roncsolt kép katasztrofálisan fog kinézni.
Íme, amikor a zöld csatornát az eredeti felbontásához képest negyedére vesszük (PS-ben ‘pixelate’ 4 pixellel):
Ezen az se segít, ha a pixelesedést egy utólagos átlagolással igyekszünk kiküszöbölni (PS-ben Gaussi blur 2 pixellel):
Ezek alapján nem kérdéses, hogy a veszteséges tömörítés az egyes csatornákon (akár részlegesen is) alkalmazva rettenetes végső minőséget adna, konkrétan teljesen elvesznének a képi részletek.
De mi van akkor, ha az YCrCb színábrázolásnál megjelenő Cr és Cb csatornákból veszünk el információt?
Tudva, hogy az Y (luminancia) csatorna hordozza a fényerő és részletgazdagság információkat, a Cr és Cb pedig csak a színeket, könnyű rájönni, hogy ezzel a módszerrel a képi részletezettség nem fog csökkenni, csak a színek finomságai csökkennek egy adott területen belül.
Az emberi szem azonban a fényerőre, kontrasztra, képélességre sokkal érzékenyebb, mint a színekre, így ezen információveszteséget sokkal nehezebb észrevennünk.
Nézzünk erre is példákat, de rögtön egy fentinél sokkal erősebb információvesztéssel kezdve.
Az első képen a Cr és Cb csatornák felbontását nyolcadára csökkentettük (8 pixeles mozaik), amelynek hatása alig látható, leginkább csak az előtérben lévő, a kép bal alsó sarkában található piros virág foltjának szélén venni észre a pixelesedést.
A második képen a pixelesedés korrekciójára 4 pixeles Gaussi blurt is alkalmaztunk a Cr és Cb csatornákon.
A harmadik és negyedik kép ugyanezt mutatja, azzal a különbséggel, hogy itt már 16 pixeles mozaikot alkalmaztunk (a Cr és Cb csatornák felbontását tizenhatodára vettük), illetve a blur esetében 8 pixeles volt a rádiusz.
Az ötödik és hatodik kép még erősebb információvesztést mutat, itt 32-ed részére vettük le a Cr és Cb csatornák felbontását, majd az ezt követő képnél 16 pixel átmérőjű elmosást adtunk ezekre a csatornákra, szimulálva ezzel egy dekódolás utáni korrekciós eljárást.
A végére azért még beraktuk újra az eredeti képünket, csak hogy össze lehessen hasonlítani a veszteséges „tömörítésű” képekkel.
Remélhetőleg mindenki jól látja, hogy a legdurvább, a Cr és Cb csatornák teljes sávszélesség igényét 32-ed részre lecsökkentő beavatkozás is inkább csak a színeket vette el, kissé kifakítva a képet, de a végső részletesség teljesen használható és élvezhető maradt.
Érdemes lehet tudnunk, hogy maga a JPEG tömörítés is ezen az elven dolgozik, azaz a világosság értékeket megtartja és csak a színi információkat tömöríti. Persze nem olyan drasztikusan, mint mi tettük, ennél azért ügyesebb algoritmust használnak, amellyel még hatékonyabb tömörítés érhető el: nagyobb veszteség és kevésbé látható hatás.
A szín-almintavételezés
Most, hogy végre megértettük, miért jó az YCrCb színábrázolás, jöhet a kiinduló témánk kifejtése, azaz a szín-almintavételezés lényege.
Képzeljünk el egy olyan tömörítési módot, ahol a luminancia csatornát igyekszünk kímélni, de emellett a színi információk mennyiségét jelentősen csökkentjük.
A ‘color subsampling’, azaz a szín-almintavételezés azt mondja meg, hogy adott pixelmennyiséghez milyen mennyiségben adunk színinformációkat.
Mi is akkor ez a 4:2:2, 4:2:0, vagy éppen 4:4:4?
A legtöbbször 4 pixel széles (és 2 pixel magas) blokkokat használnak a tömörítéshez, ezt az első számjegy írja le.
( Nagyon zárójelben, hogy csak a logikáját értsük: a 2 pixeles magasságot az elsőt követő következő számjegyek száma adja meg, azaz ha 4 pixel széles és 1 pixel magas blokkokat tömörítenének, akkor az almintavételezés összesen két számjegyből állna és így nézne ki: 4:4, vagy 4:2, vagy 4:0, ha négy pixel magas blokkot használnának, akkor az első számjegy után további négy számjegy szerepelne az almintavételezés leírásánál, valahogy így: 4:2:2:2:2, vagy 4:2:0:2:0, stb.).
A következő számjegy az első sorban lementett színinformációk számát jelzi. Ha ez négy, akkor minden pixelhez lementünk színinformációt. Ha kettő, akkor értelemszerűen minden második pixelhez mentünk le színadatot. Ha egy, akkor pedig a 4×1 pixelhez mentünk le egyetlen színadatot.
A harmadik számjegy pedig a második sorban lévő pixelekhez rendelt színinformációk számát jelzi: négy esetében szintén minden pixelhez elmentjük a színinformációt is, kettő esetében két-két pixel színinformációját vonjuk össze, egy esetében négy pixel kap egy színinformációt ebben a sorban, nulla esetében pedig a felette lévő sor pixeleivel vonjuk össze a színinformációkat (azaz 2×2 vagy 4×2 pixel kap egyetlen színinformációt).
Mindez képen kicsit látványosabb formában összefoglalva:

Azt gondolom mondanunk sem kell, hogy a fenti képen látható módon, két egymás melletti pixel esetében nagyon ritkán van ilyen mértékű színeltérés. Ez egyrészt a szenzorok felépítéséből adódik (a Bayer alapszínszűrő miatt szükséges de-mozaik eljárás egyébként sem képes létrehozni egymástól teljesen független színű pixeleket), másrészt a valóságban sincsenek ilyen éles kontúrok.
A gyakorlatban tehát inkább a fentebb lévő, fotókon bemutatott példák mutatják meg a szín-almintavételezés hatását.
Az azonban egyértelmű, hogy a sok-sok képkockát egymás után használó videóknál nagyon nem mindegy, hogy milyen erős tömörítéssel élünk, mit kell a 100, 200 vagy 400 Mbit/mp sávszélességbe belepréselni, pláne 60 kép/mp frissítésnél.
Konklúzió
Mindezekből jól látszik, hogy átlagos felhasználás esetén a 4:2:0 almintavételezés, sőt, 4k felbontás esetében akár a 4:1:0 almintavételezés is teljesen elfogadható eredményt ad(na), miközben a sávszélesség igényt jelentősen képes redukálni, ugyanakkor az utófeldolgozáshoz célszerűen magasabb részletességű, bővebb információtartalmú forrást érdemes használni, így ehhez a 4:2:2 a jobban használható (illetve ideális a 4:4:4 lenne).
Hozzá kell tegyük, hogy ez a videótömörítés egy nagyon kis szeglete csupán, leginkább az ALL-Intra módnál fontosabb. A mozgóképtömörítésnél sok esetben IPB módszert alkalmaznak, ahol nem kell minden egyes képkockát letárolni, hanem a kezdő kulcskockák (keyframe) után csak a változásokat kell (tipikusan vektoros elven) eltárolni. Ezzel iszonyúan sok adattól szabadíthatjuk meg a videófolyamot (itt gyakorlatilag a kulcskockák ismétlődési ideje határozza meg a hosszú távú videó képminőséget).
Ezért van az, hogy általában az ALL-Intra (illetve tipikusan a nagyobb sávszélesség igényű 10 bites jelfolyam) esetén kapunk csak 4:2:2 beállítási lehetőséget, hiszen IPB esetében minimális értelme van ennek, sokkal többet nyom a latba a képek között kidobható információmennyiség.
Ellenőrző kérdés
Nézzük, sikerült-e megértened a szín-almintavételezést.
A fenti ábrából kiindulva találd ki, hogyan festene egy 4:1:0 almintavételezést bemutató kép.
Ha megvan, ellenőrizd az eredményt IDE kattintva!





